<쓰레드 풀링(Pooling)>
[공부했던 것을 되짚어보며]
지금까지 쓰레드에 대한 것과 동기화에 대한 개념들을 쭉 공부해왔습니다.
쓰레드가 무엇인지, 쓰레드를 만들고 소멸시키는 것부터 동기화가 왜 필요한지에 대해서 알게 되었고요.
이제 이 쓰레드를 어떻게 활용할 수 있을까를 고민하게 되었습니다.
멀티 쓰레드 프로그래밍을 써먹을 수 있는 것은 알겠는데, 이걸 어디에 쓸까.
책에서는 "쓰레드 풀"이라는 것을 통해 지금까지 배웠던 내용을 한 번 정리할 기회를 갖게 되었습니다.
저도 이걸 따라 구현하면서 아직도 이해가 잘 안되는 부분들이 많습니다.
이번 글에서는 많이 미숙한 부분이 보일 것입니다.
그 부분에 있어서 양해 부탁드립니다.
[쓰레드 풀에 대한 이해]
우선 "쓰레드 풀"이라는 개념에 대해서 좀 이해를 하고 넘어갈까 합니다.
이게 도대체 왜 필요한 개념일까요?
우리는 지금까지 쓰레드를 생성하고 소멸하는 과정을 거치면서 바로 작업을 실행시키도록 하였습니다.
규모라고 하기에도 민망할 정도로 작은 프로그램들을 만들면서 쓰레드를 사용하는 법을 익혔죠.
그런데 실제로 프로그램은 계속 돌아가는 구조로 되어있고, 다양한 작업들을 수행하게 됩니다.
만약 어떤 일이 주어져서 쓰레드를 그때마다 생성하고 소멸해야 된다고 하면 이는 시스템에 큰 부담을 주게 됩니다.
쓰레드는 커널 오브젝트이기 때문에 쓰레드를 생성하면서 유저→커널 / 커널→유저 모드를 오가게 됩니다.
또한 쓰레드는 스케줄러, 즉 운영체제가 관리하는 대상입니다.
그래서 쓰레드의 빈번한 생성과 소멸은 속도 저하를 유발하는 원인이 됩니다.
성능의 향상을 위해서는 쓰레드의 생성과 소멸이 빈번하게 발생하지 않도록 해야합니다.
그러기 위해서 사용하는 개념이 바로 "쓰레드 풀"입니다.
다시 말해서 쓰레드를 미리 만들어서 풀에 넣어놓고, 필요하면 가져다가 쓰겠다는 개념입니다.
실제로 은행 창구 업무로 비유를 들어보면 좀 더 쉽게 이해가 될 것 같습니다.
현실에서 은행 창구 업무는 3~4명의 행원들이 업무를 처리합니다.
적을 때는 수십, 많을 때는 수백 개의 업무를 처리하게 됩니다.
업무량에 따라서 적을때는 1~2명, 많을 때는 3~4명의 행원들이 나와서 일을 처리하죠.
고객의 수만큼 행원들이 새로 생겨나는 경우는 없습니다.
만약 현실에서 이렇게 은행을 운영한다 하면 말도 안되는 것이죠.
쓰레드 풀 역시 이와 마찬가지의 개념입니다.
행원 == 쓰레드라고 볼 수 있고, 고객들의 업무 == 처리해야 할 일입니다.
위의 예시만 보더라도 쓰레드 풀을 유지하는 것은 성능 향상에 도움을 줄 수 있습니다.
쓰레드 풀의 기본적인 원리는 "쓰레드를 재활용"하는 데에 있습니다.
할당된 일을 끝마친 쓰레드를 바로 소멸시키는 것이 아니라 풀에 저장해뒀다가 필요할 때 다시 쓰는 것입니다.
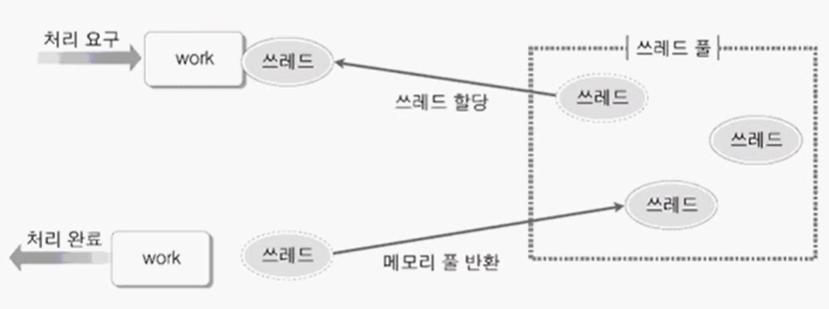
위 그림은 컴퓨터 시스템의 관점에서 쓰레드 풀 모델을 예시로 든 것입니다.
쓰레드 풀은 처리해야 할 일(work)이 등록되기 전에 생성이 됩니다.
그리고 풀이 생성됨과 동시에 쓰레드도 생성되어 풀에서 대기하게 됩니다.
실제로 지능적으로 운용되는 쓰레드 풀은 작업량의 증가 또는 감소 폭에 따라서 쓰레드의 개수를 조절하게 됩니다.
이제 쓰레드 풀이 생성된 상태에서 처리해야 할 일이 하나 등록되었다고 가정해보겠습니다.
그러면 풀에 있는 임의의 쓰레드 중 하나를 선택하여 작업을 하게 됩니다.
만약 풀에 있는 쓰레드의 수보다 처리해야 할 작업이 많다면 일이 순서대로 처리되도록 설계할 수도 있습니다.
그게 아니라면 빠른 처리를 위해서 쓰레드의 수를 증가시킬 수도 있는 것입니다.
[쓰레드 풀의 구현]
사실 쓰레드 풀은 다른 자료구조들과 마찬가지로 이미 잘 만들어져 있는 것이 있습니다.
그래서 굳이 직접 구현을 할 필요는 없습니다.
그럼에도 불구하고 쓰레드 풀을 구현하려는 이유는 자료구조를 직접 구현하는 이유와 같습니다.
우리가 자료구조를 직접 구현해보는 이유는 이 자료구조가 내부적으로 어떻게 동작하는지 이해를 하기 위함입니다.
그리고 직접 구현해보고 나서 만들어져 있는 자료구조를 사용하게 되면 보다 쉽게 접근할 수 있습니다.
쓰레드 풀 역시 같은 맥락입니다.
내부에서 어떻게 돌아가는지 알게 되면 이미 만들어져 있는 쓰레드 풀을 사용하는 데 도움이 될 수 있습니다.
물론 여기서 구현하는 코드는 저자가 제시한 코드를 따라서 구현해본 것에 불과하며, 완벽한 쓰레드 풀이 아닙니다.
[쓰레드 풀 구현의 모듈별 해석]
[쓰레드 풀의 자료구조]
우선 구현하기에 앞서서 쓰레드 풀을 구성하는 데 필요한 자료형과 함수들에 대해서 보겠습니다.
// 쓰레드에서 처리할 Work에 대한 정의.
// 반환형이 void, 매개변수도 void인 함수 포인터를 typedef 선언.
typedef void(*WORK)(void);
// 쓰레드 구조체
typedef struct _workerthread
{
HANDLE hThread;
DWORD idThread;
} WorkerThread;
// Work와 쓰레드 관리를 위한 구조체
struct _threadPool
{
WORK workList[WORK_MAX]; // Work 등록을 위한 배열
WorkerThread workerThreadList[THREAD_MAX]; // 각 쓰레드의 정보를 담기 위한 배열
HANDLE workerEventList[THREAD_MAX]; // 각 쓰레드 별 Event 오브젝트를 담기 위한
DWORD idxOfCurrentWork; // 처리 1순위 Work 인덱스
DWORD idxOfLastAddedWork; // 가장 마지막에 추가된 Work의 인덱스
// Num_Of_Thread
DWORD threadIdx; // 풀에 있는 쓰레드의 갯수
} gThreadPool; // 전역변수로 사용, 별칭을 붙이는 typedef 선언 없이 구조체 정의
우선 WORK와 같은 타입의 함수를 가리키기 위해 함수 포인터를 선언하였습니다.
이는 쓰레드에게 일을 시키기 위한 작업의 기본 단위를 정한 것입니다.
반환형은 void, 매개변수도 void인 함수로 정의했는데, 매개 변수를 받거나 반환형이 필요한 경우에는 바꾸면 됩니다.
다음은 생성되는 쓰레드의 정보를 담기 위해 WorkerThread라는 구조체를 정의하였습니다.
여기에는 쓰레드의 핸들과 쓰레드의 id를 저장하게 됩니다.
만약 우선순위와 관련된 필요한 정보들이 있다면 별도로 더 추가하셔도 됩니다.
이제 가장 핵심이 되는 쓰레드 풀의 구조체 gThreadPool 입니다.
여기에는 typedef 선언이 없이 곧바로 전역변수 형태로 사용하게 됩니다.
그래서 이 구조체 자체가 하나의 쓰레드 풀이 되는 것입니다.

여기서 workList라는 멤버는 WORK를 저장하는 배열입니다.
그리고 이와 관련된 인덱스는 idxOfCurrentWork와 idxOfLastAddedWork를 사용하고 있습니다.
하나는 처리되어야 할 작업의 위치를 가리키게 됩니다.
다른 하나는 마지막에 추가된 WORK의 인덱스보다 1 많은 값을 유지하여 새로운 WORK가 등록될 위치를 가리킵니다.
다음은 풀에 저장된 쓰레드 정보는 workerThreadList에 저장하게 됩니다.
그리고 workerEventList는 각 쓰레드 별로 하나씩 할당되는 이벤트 동기화 오브젝트(이하 이벤트)를 저장하는 배열입니다.
workerThreadList와 workerEventList는 1:1로 쌍을 이루게 됩니다.
여기서 이벤트를 사용하는 이유를 아는 것이 중요합니다. (저도 처음에는 왜 쓰는지 몰랐습니다)
이벤트가 필요한 이유는 쓰레드의 작업 여부를 결정하기 위해서 사용하게 됩니다.
"쓰레드에게 일이 부여됐다"라는 것은 쓰레드가 호출해서 실행할 함수를 지정한다는 것을 의미합니다.
만약 쓰레드에게 할당된 작업이 없다면 쓰레드는 WaitFor~ 계열의 함수를 통해 Blocked 상태로 대기하고 있어야 합니다.
그리고 새로운 작업이 할당되면 그 때 Blocked 상태에서 나와서 작업을 수행하게 됩니다.
이와 같이 제어를 하기 위해서는 쓰레드마다 이벤트가 필요하게 됩니다.
이제 마지막으로 이 예제에서는 하나 아쉬운 부분이 있습니다.
workList에 사용되는 인덱스는 증가는 하지만 감소는 하지 않는 형태입니다.
그래서 배열의 인덱스의 끝까지 등록하고 나면 추가적인 등록을 할 수 없습니다.
이 부분을 해결하기 위해서는 연결 리스트나 배열을 환형으로 만드는(환형 큐) 방법을 고려해볼 수 있습니다.
여기는 추후에 따로 구현해보시는 것도 좋은 방법입니다.
[쓰레드 풀의 함수 관계]
이 부분은 자료구조로 치면 ADT와 같은 부분이라고 볼 수 있겠습니다.
사용되는 함수들은 아래와 같습니다.
1) WORK GetWorkFromPool(void)
쓰레드 풀에서 WORK를 가져올 때 사용하는 함수.
2) DWORD AddWorkToPool(WORK work)
쓰레드 풀에 새로운 WORK를 등록할 때 사용하는 함수.
3) DWORD MakeThreadToPool(DWORD numOfThread)
쓰레드 풀이 생성된 이후에 풀에 쓰레드를 생성(등록)하는 함수.
인자로 전달되는 수만큼 쓰레드가 생성.
4) void WorkerThreadFunction(LPVOID pParam)
쓰레드가 생성되자마자 호출하는 쓰레드의 main 함수.
실질적으로 WORK를 할당하고 처리하는 과정과 WORK가 없을 때의 쓰레드 상태 제어를 담당.

구현하게 될 쓰레드 풀의 메커니즘과 함수들의 관계를 정리하면 위의 그림과 같이 됩니다.
[전역으로 선언된 쓰레드 풀 접근 동기화]
쓰레드 풀에 해당하는 gThreadPool은 전역으로 선언해놓았습니다.
그래서 둘 이상의 쓰레드에 의해 참조가 가능한 메모리 영역입니다.
그러므로 gThreadPool에 대해서는 동기화를 할 필요가 있습니다.
동기화를 위해 뮤텍스를 사용하였고, 다음 함수들은 뮤텍스 기반 동기화 함수들을 래핑(Wrapping)한 함수들입니다.
void InitMutex(void);
void DeInitMutex(void);
void AcquireMutex(void);
void ReleaseMutex(void);
여기서 왜 굳이 래핑을 하는가 싶은 분들이 있을 수도 있습니다.
그냥 CreateMutex, CloseHandle, WaitForSingleObject로 바로 쓰면 되는거 아니냐 하실텐데요.
코드의 가독성을 높이기 위한 것이 일단 첫 번째 목적입니다.
그리고 일부 함수의 경우에는 인라인(inline)화가 되어 함수의 호출이 함수의 정의가 그대로 들어가기도 합니다.
인라인에 대한 개념이 궁금하신 분들은 따로 찾아보시면 뭔지 바로 이해가 되실겁니다.
[쓰레드 풀 구현 소스 코드]
이제 쓰레드 풀을 구현한 소스 코드를 보도록 하겠습니다.
사실 따라서 치는 것보다는 코드가 내부적으로 어떻게 동작하는지를 이해하시는 것이 더 중요합니다.
[ThreadPooling.cpp]
/*
* Windows System Programming - 쓰레드 풀링(Pooling)
* 파일명: ThreadPooling.cpp
* 파일 버전: 0.1
* 작성자: Sevenshards
* 작성 일자: 2023-12-09
* 이전 버전 작성 일자:
* 버전 내용: 기본적인 쓰레드 풀(Thread Pool) 구현
* 이전 버전 내용:
*/
#include <stdio.h>
#include <tchar.h>
#include <Windows.h>
#include <process.h>
#define WORK_MAX 10000
#define THREAD_MAX 50
// 쓰레드에서 처리할 Work에 대한 정의.
// 반환형이 void, 매개변수도 void인 함수 포인터를 typedef 선언.
typedef void(*WORK)(void);
// 쓰레드 풀의 ADT
DWORD AddWorkToPool(WORK work); // 새로운 Work를 쓰레드 풀에 등록
WORK GetWorkFromPool(void); // 쓰레드 풀에서 Work을 가져올 때 호출하는 함수
DWORD MakeThreadToPool(DWORD numOfThread); // 쓰레드 풀을 생성한 이후 풀에 쓰레드를 생성(등록)하는 함수, 인자의 수만큼 쓰레드 생성
void WorkerThreadFunction(LPVOID lpParam); // 쓰레드가 생성되자마자 호출하는 쓰레드의 main 함수
// 쓰레드 구조체
typedef struct _workerthread
{
HANDLE hThread;
DWORD idThread;
} WorkerThread;
// Work와 쓰레드 관리를 위한 구조체
struct _threadPool
{
WORK workList[WORK_MAX]; // Work 등록을 위한 배열
WorkerThread workerThreadList[THREAD_MAX]; // 각 쓰레드의 정보를 담기 위한 배열
HANDLE workerEventList[THREAD_MAX]; // 각 쓰레드 별 Event 오브젝트를 담기 위한
DWORD idxOfCurrentWork; // 처리 1순위 Work 인덱스
DWORD idxOfLastAddedWork; // 가장 마지막에 추가된 Work의 인덱스
// Num_Of_Thread
DWORD threadIdx; // 풀에 있는 쓰레드의 갯수
} gThreadPool; // 전역변수로 사용, 별칭을 붙이는 typedef 선언 없이 구조체 정의
// 뮤텍스 관련 함수 정의 부분 시작
static HANDLE mutex = NULL; // 뮤텍스를 static 전역 변수로 선언 -> 이 파일 내에서만 유효하다.
// 뮤텍스 생성
void InitMutex(void)
{
mutex = CreateMutex(NULL, FALSE, NULL);
if (mutex == NULL)
_tprintf(TEXT("CreateMutex Failed, Error Code: %d\n"), GetLastError());
}
// 뮤텍스의 핸들 반환, Usage Count 1 감소
void CloseMutex(void)
{
BOOL ret = CloseHandle(mutex);
if (ret == 0)
_tprintf(TEXT("CloseHadle Failed, Error Code: %d\n"), GetLastError());
}
// 뮤텍스를 획득
void AcquireMutex(void)
{
DWORD ret = WaitForSingleObject(mutex, INFINITE);
if (ret == WAIT_FAILED)
_tprintf(TEXT("Error Occured, Error Code: %d\n"), GetLastError());
}
// 뮤텍스를 반환 (C++이므로 함수 오버로딩 가능)
void ReleaseMutex(void)
{
BOOL ret = ReleaseMutex(mutex);
if (ret == 0)
_tprintf(TEXT("Error Occured, Error Code: %d\n"), GetLastError());
}
// 뮤텍스 관련 함수 정의 부분 끝
// 쓰레드 풀 관련 함수 정의 부분 시작
// 쓰레드 풀에 Work를 등록시키기 위한 함수
DWORD AddWorkToPool(WORK work)
{
AcquireMutex();
if (gThreadPool.idxOfLastAddedWork >= WORK_MAX)
{
_tprintf(TEXT("AddWorkToPool Failed, Error Code: %d\n"), GetLastError());
return NULL;
}
// Work 등록
gThreadPool.workList[gThreadPool.idxOfLastAddedWork++] = work;
// Work 등록 후, 대기 중인 쓰레드를 모두 실행시켜서 작업을 처리함
// 사실 모든 쓰레드를 실행시킬 필요는 없어서 효율성이 떨어짐 -> 개선 가능하다면 개선하는 것이 좋음
for (DWORD i = 0; i < gThreadPool.threadIdx; i++)
SetEvent(gThreadPool.workerEventList[i]);
ReleaseMutex();
return 1;
}
// 쓰레드 풀에서 Work를 가져올 때 호출되는 함수
// gThreadPool에 대한 접근을 보호하기 위해 정의
WORK GetWorkFromPool()
{
WORK work = NULL;
AcquireMutex();
// 현재 처리해야 할 Work가 없다면
if (!(gThreadPool.idxOfCurrentWork < gThreadPool.idxOfLastAddedWork))
{
ReleaseMutex();
return NULL;
}
work = gThreadPool.workList[gThreadPool.idxOfCurrentWork++];
ReleaseMutex();
return work;
}
// 쓰레드 풀 생성
// 전달되는 인자의 값만큼 쓰레드를 생성
DWORD MakeThreadToPool(DWORD numOfThread)
{
InitMutex();
DWORD capacity = WORK_MAX - (gThreadPool.threadIdx);
if (capacity < numOfThread)
numOfThread = capacity;
for (DWORD i = 0; i < numOfThread; i++)
{
DWORD idThread;
HANDLE hThread;
gThreadPool.workerEventList[gThreadPool.threadIdx]
= CreateEvent(NULL, FALSE, FALSE, NULL);
hThread = (HANDLE)_beginthreadex(
NULL,
0,
(_beginthreadex_proc_type)WorkerThreadFunction,
(LPVOID)gThreadPool.threadIdx,
0,
(unsigned*)&idThread
);
gThreadPool.workerThreadList[gThreadPool.threadIdx].hThread = hThread;
gThreadPool.workerThreadList[gThreadPool.threadIdx].idThread = idThread;
(gThreadPool.threadIdx++);
}
return numOfThread;
}
void WorkerThreadFunction(LPVOID lpParam)
{
WORK workFunction;
HANDLE event = gThreadPool.workerEventList[(DWORD)lpParam];
while (1)
{
workFunction = GetWorkFromPool();
if (workFunction == NULL)
{
// Work가 할당될 때까지 Blocked 상태
WaitForSingleObject(event, INFINITE);
continue;
}
workFunction();
}
}
// 쓰레드 풀 관련 함수 정의 부분 끝
// 단순한 Work Function
void TestFunction()
{
// i는 static 변수 -> DATA 영역에 할당
// 쓰레드에 의해 동시 접근이 가능하다
// 동기화가 필요하지만 현 시점에서는 생략.
static int i = 0;
i++;
_tprintf(TEXT("Good Test -- %d: Processing thread: %d\n\n"), i, GetCurrentThreadId());
}
int _tmain(int argc, TCHAR* argv[])
{
MakeThreadToPool(3);
// 다수의 Work를 등록
for (DWORD i = 0; i < 100; i++)
AddWorkToPool(TestFunction);
Sleep(50000);
return 0;
}
+ 글을 마치면서
이것으로 쓰레드와 동기화에 대한 전반적인 개념을 마무리하였습니다.
다음 글부터는 책의 마지막인 4장을 다루게 됩니다.
여기서는 메모리 관리와 비동기 I/O에 대한 부분을 주로 다루게 됩니다.
이제 책의 내용 정리의 끝까지 얼마 안남았습니다.
끝은 아니지만 지금까지 공부하면서 느꼈던 제 나름대로의 이야기를 적고 싶어서 좀 적어볼까 합니다.
저는 지금까지 윈도우즈 시스템 프로그래밍에 대한 내용을 복습차원에서 정리를 해왔습니다.
초반에는 책을 따라서 정리한 내용이 대부분이었고, 이후에는 제 나름대로의 해석을 하려고 한 부분들도 있었습니다.
윈도우즈 시스템 프로그래밍을 처음 접하기에 아무래도 어려운 내용들도 많았습니다.
특히 컴퓨터 구조나 OS에 대한 기반 지식이 약하면 큰 어려움이 따른다는 것을 많이 실감하기도 했습니다.
그래서 저에게 부족한 부분을 채워나가기 위해서는 무엇이 필요한가를 생각할 기회를 가질 수도 있었고요.
솔직히 말하자면 책을 읽고, 강의를 들으면서 또 읽고, 마지막으로 이 글을 정리하면서 책을 세 번은 읽어보았습니다.
그럼에도 불구하고 몇몇 개념들은 아직도 확립이 잘 안되어있습니다.
한 번에 딱 보고 이해가 되고 오래오래 기억에 남으면 좋겠지만, 사람이라는게 매번 까먹고 살게됩니다.
그러니 바로 이해가 안되고 기억이 안난다고 포기하지 말고 자주, 오래 보는 것이 중요한 것 같습니다.
그러다보면 어느 순간 탁 하고 트이는 순간이 오긴 옵니다.
그 때가 언제라고는 딱 잘라서 말을 드릴 수는 없지만 분명히 있긴 있습니다.
저도 머리가 좋다거나 영리한 사람이 아니기에 탁 트이는 그 한 순간을 위해서 계속 노력을 하게 되는 것 같습니다.
그러니 저를 포함해서 프로그래밍을 공부하시는 분들에게 포기하지 말고 계속 나아가라는 말을 하고 싶습니다.
<쓰레드 풀링(Pooling)>
[공부했던 것을 되짚어보며]
지금까지 쓰레드에 대한 것과 동기화에 대한 개념들을 쭉 공부해왔습니다.
쓰레드가 무엇인지, 쓰레드를 만들고 소멸시키는 것부터 동기화가 왜 필요한지에 대해서 알게 되었고요.
이제 이 쓰레드를 어떻게 활용할 수 있을까를 고민하게 되었습니다.
멀티 쓰레드 프로그래밍을 써먹을 수 있는 것은 알겠는데, 이걸 어디에 쓸까.
책에서는 "쓰레드 풀"이라는 것을 통해 지금까지 배웠던 내용을 한 번 정리할 기회를 갖게 되었습니다.
저도 이걸 따라 구현하면서 아직도 이해가 잘 안되는 부분들이 많습니다.
이번 글에서는 많이 미숙한 부분이 보일 것입니다.
그 부분에 있어서 양해 부탁드립니다.
[쓰레드 풀에 대한 이해]
우선 "쓰레드 풀"이라는 개념에 대해서 좀 이해를 하고 넘어갈까 합니다.
이게 도대체 왜 필요한 개념일까요?
우리는 지금까지 쓰레드를 생성하고 소멸하는 과정을 거치면서 바로 작업을 실행시키도록 하였습니다.
규모라고 하기에도 민망할 정도로 작은 프로그램들을 만들면서 쓰레드를 사용하는 법을 익혔죠.
그런데 실제로 프로그램은 계속 돌아가는 구조로 되어있고, 다양한 작업들을 수행하게 됩니다.
만약 어떤 일이 주어져서 쓰레드를 그때마다 생성하고 소멸해야 된다고 하면 이는 시스템에 큰 부담을 주게 됩니다.
쓰레드는 커널 오브젝트이기 때문에 쓰레드를 생성하면서 유저→커널 / 커널→유저 모드를 오가게 됩니다.
또한 쓰레드는 스케줄러, 즉 운영체제가 관리하는 대상입니다.
그래서 쓰레드의 빈번한 생성과 소멸은 속도 저하를 유발하는 원인이 됩니다.
성능의 향상을 위해서는 쓰레드의 생성과 소멸이 빈번하게 발생하지 않도록 해야합니다.
그러기 위해서 사용하는 개념이 바로 "쓰레드 풀"입니다.
다시 말해서 쓰레드를 미리 만들어서 풀에 넣어놓고, 필요하면 가져다가 쓰겠다는 개념입니다.
실제로 은행 창구 업무로 비유를 들어보면 좀 더 쉽게 이해가 될 것 같습니다.
현실에서 은행 창구 업무는 3~4명의 행원들이 업무를 처리합니다.
적을 때는 수십, 많을 때는 수백 개의 업무를 처리하게 됩니다.
업무량에 따라서 적을때는 1~2명, 많을 때는 3~4명의 행원들이 나와서 일을 처리하죠.
고객의 수만큼 행원들이 새로 생겨나는 경우는 없습니다.
만약 현실에서 이렇게 은행을 운영한다 하면 말도 안되는 것이죠.
쓰레드 풀 역시 이와 마찬가지의 개념입니다.
행원 == 쓰레드라고 볼 수 있고, 고객들의 업무 == 처리해야 할 일입니다.
위의 예시만 보더라도 쓰레드 풀을 유지하는 것은 성능 향상에 도움을 줄 수 있습니다.
쓰레드 풀의 기본적인 원리는 "쓰레드를 재활용"하는 데에 있습니다.
할당된 일을 끝마친 쓰레드를 바로 소멸시키는 것이 아니라 풀에 저장해뒀다가 필요할 때 다시 쓰는 것입니다.
위 그림은 컴퓨터 시스템의 관점에서 쓰레드 풀 모델을 예시로 든 것입니다.
쓰레드 풀은 처리해야 할 일(work)이 등록되기 전에 생성이 됩니다.
그리고 풀이 생성됨과 동시에 쓰레드도 생성되어 풀에서 대기하게 됩니다.
실제로 지능적으로 운용되는 쓰레드 풀은 작업량의 증가 또는 감소 폭에 따라서 쓰레드의 개수를 조절하게 됩니다.
이제 쓰레드 풀이 생성된 상태에서 처리해야 할 일이 하나 등록되었다고 가정해보겠습니다.
그러면 풀에 있는 임의의 쓰레드 중 하나를 선택하여 작업을 하게 됩니다.
만약 풀에 있는 쓰레드의 수보다 처리해야 할 작업이 많다면 일이 순서대로 처리되도록 설계할 수도 있습니다.
그게 아니라면 빠른 처리를 위해서 쓰레드의 수를 증가시킬 수도 있는 것입니다.
[쓰레드 풀의 구현]
사실 쓰레드 풀은 다른 자료구조들과 마찬가지로 이미 잘 만들어져 있는 것이 있습니다.
그래서 굳이 직접 구현을 할 필요는 없습니다.
그럼에도 불구하고 쓰레드 풀을 구현하려는 이유는 자료구조를 직접 구현하는 이유와 같습니다.
우리가 자료구조를 직접 구현해보는 이유는 이 자료구조가 내부적으로 어떻게 동작하는지 이해를 하기 위함입니다.
그리고 직접 구현해보고 나서 만들어져 있는 자료구조를 사용하게 되면 보다 쉽게 접근할 수 있습니다.
쓰레드 풀 역시 같은 맥락입니다.
내부에서 어떻게 돌아가는지 알게 되면 이미 만들어져 있는 쓰레드 풀을 사용하는 데 도움이 될 수 있습니다.
물론 여기서 구현하는 코드는 저자가 제시한 코드를 따라서 구현해본 것에 불과하며, 완벽한 쓰레드 풀이 아닙니다.
[쓰레드 풀 구현의 모듈별 해석]
[쓰레드 풀의 자료구조]
우선 구현하기에 앞서서 쓰레드 풀을 구성하는 데 필요한 자료형과 함수들에 대해서 보겠습니다.
// 쓰레드에서 처리할 Work에 대한 정의.
// 반환형이 void, 매개변수도 void인 함수 포인터를 typedef 선언.
typedef void(*WORK)(void);
// 쓰레드 구조체
typedef struct _workerthread
{
HANDLE hThread;
DWORD idThread;
} WorkerThread;
// Work와 쓰레드 관리를 위한 구조체
struct _threadPool
{
WORK workList[WORK_MAX]; // Work 등록을 위한 배열
WorkerThread workerThreadList[THREAD_MAX]; // 각 쓰레드의 정보를 담기 위한 배열
HANDLE workerEventList[THREAD_MAX]; // 각 쓰레드 별 Event 오브젝트를 담기 위한
DWORD idxOfCurrentWork; // 처리 1순위 Work 인덱스
DWORD idxOfLastAddedWork; // 가장 마지막에 추가된 Work의 인덱스
// Num_Of_Thread
DWORD threadIdx; // 풀에 있는 쓰레드의 갯수
} gThreadPool; // 전역변수로 사용, 별칭을 붙이는 typedef 선언 없이 구조체 정의
우선 WORK와 같은 타입의 함수를 가리키기 위해 함수 포인터를 선언하였습니다.
이는 쓰레드에게 일을 시키기 위한 작업의 기본 단위를 정한 것입니다.
반환형은 void, 매개변수도 void인 함수로 정의했는데, 매개 변수를 받거나 반환형이 필요한 경우에는 바꾸면 됩니다.
다음은 생성되는 쓰레드의 정보를 담기 위해 WorkerThread라는 구조체를 정의하였습니다.
여기에는 쓰레드의 핸들과 쓰레드의 id를 저장하게 됩니다.
만약 우선순위와 관련된 필요한 정보들이 있다면 별도로 더 추가하셔도 됩니다.
이제 가장 핵심이 되는 쓰레드 풀의 구조체 gThreadPool 입니다.
여기에는 typedef 선언이 없이 곧바로 전역변수 형태로 사용하게 됩니다.
그래서 이 구조체 자체가 하나의 쓰레드 풀이 되는 것입니다.
여기서 workList라는 멤버는 WORK를 저장하는 배열입니다.
그리고 이와 관련된 인덱스는 idxOfCurrentWork와 idxOfLastAddedWork를 사용하고 있습니다.
하나는 처리되어야 할 작업의 위치를 가리키게 됩니다.
다른 하나는 마지막에 추가된 WORK의 인덱스보다 1 많은 값을 유지하여 새로운 WORK가 등록될 위치를 가리킵니다.
다음은 풀에 저장된 쓰레드 정보는 workerThreadList에 저장하게 됩니다.
그리고 workerEventList는 각 쓰레드 별로 하나씩 할당되는 이벤트 동기화 오브젝트(이하 이벤트)를 저장하는 배열입니다.
workerThreadList와 workerEventList는 1:1로 쌍을 이루게 됩니다.
여기서 이벤트를 사용하는 이유를 아는 것이 중요합니다. (저도 처음에는 왜 쓰는지 몰랐습니다)
이벤트가 필요한 이유는 쓰레드의 작업 여부를 결정하기 위해서 사용하게 됩니다.
"쓰레드에게 일이 부여됐다"라는 것은 쓰레드가 호출해서 실행할 함수를 지정한다는 것을 의미합니다.
만약 쓰레드에게 할당된 작업이 없다면 쓰레드는 WaitFor~ 계열의 함수를 통해 Blocked 상태로 대기하고 있어야 합니다.
그리고 새로운 작업이 할당되면 그 때 Blocked 상태에서 나와서 작업을 수행하게 됩니다.
이와 같이 제어를 하기 위해서는 쓰레드마다 이벤트가 필요하게 됩니다.
이제 마지막으로 이 예제에서는 하나 아쉬운 부분이 있습니다.
workList에 사용되는 인덱스는 증가는 하지만 감소는 하지 않는 형태입니다.
그래서 배열의 인덱스의 끝까지 등록하고 나면 추가적인 등록을 할 수 없습니다.
이 부분을 해결하기 위해서는 연결 리스트나 배열을 환형으로 만드는(환형 큐) 방법을 고려해볼 수 있습니다.
여기는 추후에 따로 구현해보시는 것도 좋은 방법입니다.
[쓰레드 풀의 함수 관계]
이 부분은 자료구조로 치면 ADT와 같은 부분이라고 볼 수 있겠습니다.
사용되는 함수들은 아래와 같습니다.
1) WORK GetWorkFromPool(void)
쓰레드 풀에서 WORK를 가져올 때 사용하는 함수.
2) DWORD AddWorkToPool(WORK work)
쓰레드 풀에 새로운 WORK를 등록할 때 사용하는 함수.
3) DWORD MakeThreadToPool(DWORD numOfThread)
쓰레드 풀이 생성된 이후에 풀에 쓰레드를 생성(등록)하는 함수.
인자로 전달되는 수만큼 쓰레드가 생성.
4) void WorkerThreadFunction(LPVOID pParam)
쓰레드가 생성되자마자 호출하는 쓰레드의 main 함수.
실질적으로 WORK를 할당하고 처리하는 과정과 WORK가 없을 때의 쓰레드 상태 제어를 담당.
구현하게 될 쓰레드 풀의 메커니즘과 함수들의 관계를 정리하면 위의 그림과 같이 됩니다.
[전역으로 선언된 쓰레드 풀 접근 동기화]
쓰레드 풀에 해당하는 gThreadPool은 전역으로 선언해놓았습니다.
그래서 둘 이상의 쓰레드에 의해 참조가 가능한 메모리 영역입니다.
그러므로 gThreadPool에 대해서는 동기화를 할 필요가 있습니다.
동기화를 위해 뮤텍스를 사용하였고, 다음 함수들은 뮤텍스 기반 동기화 함수들을 래핑(Wrapping)한 함수들입니다.
void InitMutex(void);
void DeInitMutex(void);
void AcquireMutex(void);
void ReleaseMutex(void);
여기서 왜 굳이 래핑을 하는가 싶은 분들이 있을 수도 있습니다.
그냥 CreateMutex, CloseHandle, WaitForSingleObject로 바로 쓰면 되는거 아니냐 하실텐데요.
코드의 가독성을 높이기 위한 것이 일단 첫 번째 목적입니다.
그리고 일부 함수의 경우에는 인라인(inline)화가 되어 함수의 호출이 함수의 정의가 그대로 들어가기도 합니다.
인라인에 대한 개념이 궁금하신 분들은 따로 찾아보시면 뭔지 바로 이해가 되실겁니다.
[쓰레드 풀 구현 소스 코드]
이제 쓰레드 풀을 구현한 소스 코드를 보도록 하겠습니다.
사실 따라서 치는 것보다는 코드가 내부적으로 어떻게 동작하는지를 이해하시는 것이 더 중요합니다.
[ThreadPooling.cpp]
/*
* Windows System Programming - 쓰레드 풀링(Pooling)
* 파일명: ThreadPooling.cpp
* 파일 버전: 0.1
* 작성자: Sevenshards
* 작성 일자: 2023-12-09
* 이전 버전 작성 일자:
* 버전 내용: 기본적인 쓰레드 풀(Thread Pool) 구현
* 이전 버전 내용:
*/
#include <stdio.h>
#include <tchar.h>
#include <Windows.h>
#include <process.h>
#define WORK_MAX 10000
#define THREAD_MAX 50
// 쓰레드에서 처리할 Work에 대한 정의.
// 반환형이 void, 매개변수도 void인 함수 포인터를 typedef 선언.
typedef void(*WORK)(void);
// 쓰레드 풀의 ADT
DWORD AddWorkToPool(WORK work); // 새로운 Work를 쓰레드 풀에 등록
WORK GetWorkFromPool(void); // 쓰레드 풀에서 Work을 가져올 때 호출하는 함수
DWORD MakeThreadToPool(DWORD numOfThread); // 쓰레드 풀을 생성한 이후 풀에 쓰레드를 생성(등록)하는 함수, 인자의 수만큼 쓰레드 생성
void WorkerThreadFunction(LPVOID lpParam); // 쓰레드가 생성되자마자 호출하는 쓰레드의 main 함수
// 쓰레드 구조체
typedef struct _workerthread
{
HANDLE hThread;
DWORD idThread;
} WorkerThread;
// Work와 쓰레드 관리를 위한 구조체
struct _threadPool
{
WORK workList[WORK_MAX]; // Work 등록을 위한 배열
WorkerThread workerThreadList[THREAD_MAX]; // 각 쓰레드의 정보를 담기 위한 배열
HANDLE workerEventList[THREAD_MAX]; // 각 쓰레드 별 Event 오브젝트를 담기 위한
DWORD idxOfCurrentWork; // 처리 1순위 Work 인덱스
DWORD idxOfLastAddedWork; // 가장 마지막에 추가된 Work의 인덱스
// Num_Of_Thread
DWORD threadIdx; // 풀에 있는 쓰레드의 갯수
} gThreadPool; // 전역변수로 사용, 별칭을 붙이는 typedef 선언 없이 구조체 정의
// 뮤텍스 관련 함수 정의 부분 시작
static HANDLE mutex = NULL; // 뮤텍스를 static 전역 변수로 선언 -> 이 파일 내에서만 유효하다.
// 뮤텍스 생성
void InitMutex(void)
{
mutex = CreateMutex(NULL, FALSE, NULL);
if (mutex == NULL)
_tprintf(TEXT("CreateMutex Failed, Error Code: %d\n"), GetLastError());
}
// 뮤텍스의 핸들 반환, Usage Count 1 감소
void CloseMutex(void)
{
BOOL ret = CloseHandle(mutex);
if (ret == 0)
_tprintf(TEXT("CloseHadle Failed, Error Code: %d\n"), GetLastError());
}
// 뮤텍스를 획득
void AcquireMutex(void)
{
DWORD ret = WaitForSingleObject(mutex, INFINITE);
if (ret == WAIT_FAILED)
_tprintf(TEXT("Error Occured, Error Code: %d\n"), GetLastError());
}
// 뮤텍스를 반환 (C++이므로 함수 오버로딩 가능)
void ReleaseMutex(void)
{
BOOL ret = ReleaseMutex(mutex);
if (ret == 0)
_tprintf(TEXT("Error Occured, Error Code: %d\n"), GetLastError());
}
// 뮤텍스 관련 함수 정의 부분 끝
// 쓰레드 풀 관련 함수 정의 부분 시작
// 쓰레드 풀에 Work를 등록시키기 위한 함수
DWORD AddWorkToPool(WORK work)
{
AcquireMutex();
if (gThreadPool.idxOfLastAddedWork >= WORK_MAX)
{
_tprintf(TEXT("AddWorkToPool Failed, Error Code: %d\n"), GetLastError());
return NULL;
}
// Work 등록
gThreadPool.workList[gThreadPool.idxOfLastAddedWork++] = work;
// Work 등록 후, 대기 중인 쓰레드를 모두 실행시켜서 작업을 처리함
// 사실 모든 쓰레드를 실행시킬 필요는 없어서 효율성이 떨어짐 -> 개선 가능하다면 개선하는 것이 좋음
for (DWORD i = 0; i < gThreadPool.threadIdx; i++)
SetEvent(gThreadPool.workerEventList[i]);
ReleaseMutex();
return 1;
}
// 쓰레드 풀에서 Work를 가져올 때 호출되는 함수
// gThreadPool에 대한 접근을 보호하기 위해 정의
WORK GetWorkFromPool()
{
WORK work = NULL;
AcquireMutex();
// 현재 처리해야 할 Work가 없다면
if (!(gThreadPool.idxOfCurrentWork < gThreadPool.idxOfLastAddedWork))
{
ReleaseMutex();
return NULL;
}
work = gThreadPool.workList[gThreadPool.idxOfCurrentWork++];
ReleaseMutex();
return work;
}
// 쓰레드 풀 생성
// 전달되는 인자의 값만큼 쓰레드를 생성
DWORD MakeThreadToPool(DWORD numOfThread)
{
InitMutex();
DWORD capacity = WORK_MAX - (gThreadPool.threadIdx);
if (capacity < numOfThread)
numOfThread = capacity;
for (DWORD i = 0; i < numOfThread; i++)
{
DWORD idThread;
HANDLE hThread;
gThreadPool.workerEventList[gThreadPool.threadIdx]
= CreateEvent(NULL, FALSE, FALSE, NULL);
hThread = (HANDLE)_beginthreadex(
NULL,
0,
(_beginthreadex_proc_type)WorkerThreadFunction,
(LPVOID)gThreadPool.threadIdx,
0,
(unsigned*)&idThread
);
gThreadPool.workerThreadList[gThreadPool.threadIdx].hThread = hThread;
gThreadPool.workerThreadList[gThreadPool.threadIdx].idThread = idThread;
(gThreadPool.threadIdx++);
}
return numOfThread;
}
void WorkerThreadFunction(LPVOID lpParam)
{
WORK workFunction;
HANDLE event = gThreadPool.workerEventList[(DWORD)lpParam];
while (1)
{
workFunction = GetWorkFromPool();
if (workFunction == NULL)
{
// Work가 할당될 때까지 Blocked 상태
WaitForSingleObject(event, INFINITE);
continue;
}
workFunction();
}
}
// 쓰레드 풀 관련 함수 정의 부분 끝
// 단순한 Work Function
void TestFunction()
{
// i는 static 변수 -> DATA 영역에 할당
// 쓰레드에 의해 동시 접근이 가능하다
// 동기화가 필요하지만 현 시점에서는 생략.
static int i = 0;
i++;
_tprintf(TEXT("Good Test -- %d: Processing thread: %d\n\n"), i, GetCurrentThreadId());
}
int _tmain(int argc, TCHAR* argv[])
{
MakeThreadToPool(3);
// 다수의 Work를 등록
for (DWORD i = 0; i < 100; i++)
AddWorkToPool(TestFunction);
Sleep(50000);
return 0;
}
+ 글을 마치면서
이것으로 쓰레드와 동기화에 대한 전반적인 개념을 마무리하였습니다.
다음 글부터는 책의 마지막인 4장을 다루게 됩니다.
여기서는 메모리 관리와 비동기 I/O에 대한 부분을 주로 다루게 됩니다.
이제 책의 내용 정리의 끝까지 얼마 안남았습니다.
끝은 아니지만 지금까지 공부하면서 느꼈던 제 나름대로의 이야기를 적고 싶어서 좀 적어볼까 합니다.
저는 지금까지 윈도우즈 시스템 프로그래밍에 대한 내용을 복습차원에서 정리를 해왔습니다.
초반에는 책을 따라서 정리한 내용이 대부분이었고, 이후에는 제 나름대로의 해석을 하려고 한 부분들도 있었습니다.
윈도우즈 시스템 프로그래밍을 처음 접하기에 아무래도 어려운 내용들도 많았습니다.
특히 컴퓨터 구조나 OS에 대한 기반 지식이 약하면 큰 어려움이 따른다는 것을 많이 실감하기도 했습니다.
그래서 저에게 부족한 부분을 채워나가기 위해서는 무엇이 필요한가를 생각할 기회를 가질 수도 있었고요.
솔직히 말하자면 책을 읽고, 강의를 들으면서 또 읽고, 마지막으로 이 글을 정리하면서 책을 세 번은 읽어보았습니다.
그럼에도 불구하고 몇몇 개념들은 아직도 확립이 잘 안되어있습니다.
한 번에 딱 보고 이해가 되고 오래오래 기억에 남으면 좋겠지만, 사람이라는게 매번 까먹고 살게됩니다.
그러니 바로 이해가 안되고 기억이 안난다고 포기하지 말고 자주, 오래 보는 것이 중요한 것 같습니다.
그러다보면 어느 순간 탁 하고 트이는 순간이 오긴 옵니다.
그 때가 언제라고는 딱 잘라서 말을 드릴 수는 없지만 분명히 있긴 있습니다.
저도 머리가 좋다거나 영리한 사람이 아니기에 탁 트이는 그 한 순간을 위해서 계속 노력을 하게 되는 것 같습니다.
그러니 저를 포함해서 프로그래밍을 공부하시는 분들에게 포기하지 말고 계속 나아가라는 말을 하고 싶습니다.