<스케줄링 알고리즘과 우선순위>
[공부 했던 것을 되짚어보며]
책으로 치면 어느덧 2장의 끝에 왔습니다.
지금까지 컴퓨터 구조에 대한 이야기도 했었고, 프로세스에 대한 이야기도 했었죠.
그리고 커널 오브젝트와 핸들, 핸들 테이블에 대한 이야기도 했습니다.
특히 이 커널 오브젝트라는 개념이 뒤에 가서도 굉장히 많이 언급이 될겁니다.
저는 4장 이전까지 공부를 하고 복습 차원에서 글을 작성하고 있습니다.
여기서 다뤘던 커널 오브젝트와 핸들부터 핸들 테이블까지의 개념은 잘 정리해두시길 바랍니다.
뒤에 가서 이 개념을 모르면 진짜 11챕터까지 가서 7~8챕터를 오락가락하게 됩니다.
개인적인 잡소리가 더 길어지면 안되니까 공부했던 것을 정리해보겠습니다.
[프로세스의 스케줄링(Scheduling]
우리가 쉽게 접하는 대부분의 운영체제는 멀티 프로세스 기반의 운영체제입니다.
물론 운영체제마다 제공하는 시스템 함수들은 조금씩 차이가 있습니다.
하지만 목적은 같습니다.
우리가 앞서 배워왔던 프로세스 생성과 소멸에 대한 시스템 함수를 유닉스나 리눅스에서도 지원합니다.
프로세스간 통신 기법도 똑같이 지원합니다.
결과적으로는 여기나 거기나 프로세스라는 개념은 중요하다는 것입니다.
이제 본론으로 넘어오겠습니다.
프로세스는 실행 중인 하나의 프로그램입니다.
그리고 하나의 프로그램이 실행되기 위해서는 하나의 CPU(정확히는 코어)가 필요합니다.
프로세스 수만큼 CPU가 있으면 정말 좋겠죠.
그런데 우리가 쓰는 PC에는 CPU가 몇개인가요? 단 하나입니다.
요즘에는 CPU의 코어수가 많아져서 하나로도 충분한 세상이긴 합니다.
두 자릿수의 코어가 기본인 세상이잖아요.
(싱글, 듀얼코어 CPU를 쓰면 천연기념물(?)이라고 봐야 할 수준)
그런데 우리가 실제로 실행하는 프로그램의 갯수는 얼마나 될까요?
20개는 넘어가는 분들이 많으실겁니다. 코어 갯수는 거뜬히 넘기는거죠.
이번에 다룰 주제는 '스케줄러(Scheduler)'라는 놈입니다.
이전 글에서도 프로세스 스케줄링이 왜 필요한지, 프로세스의 상태도 공부를 했었죠.
https://sevenshards.tistory.com/43
[Windows System Programming] 프로세스의 생성과 소멸
[프로세스의 이해] 현재 운영체제는 "멀티 프로세스(Multi-Process) 운영체제"라고 한다. 쉽게 말하면 "프로세스라는 것이 여러개 존재할 수 있는 운영체제"를 말한다. 여기서 프로세스라는 것을 뭘
sevenshards.tistory.com
기억이 안나신다면 다시 보고 오는 것도 좋습니다.
프로세스가 CPU에 골고루 할당되기 위해서는 프로세스 스케줄링이 필요합니다.
그리고 이 일을 하는 것은 멀티 프로세스를 지원하는 운영체제에서 담당하게 됩니다.
그 중에서도 '스케줄러'라는 놈이 이 일을 하는 것입니다.
[일반 OS와 리얼타임(Real Time) OS의 차이점]
스케줄러 이야기를 한다면서, 운영체제의 차이점?
뭔 뜬금없는 주제인가 싶으실겁니다.
결론만 먼저 짚고 넘어간다면, 이 둘은 스케줄러의 차이가 있습니다.
우선 일반 OS는 우리가 사용하고 있는 Windows나 리눅스 같은 것들이 있겠네요.
그럼 Real Time OS(줄여서 RTOS)는 뭐냐?
일단 앞에 실시간이라는 단어가 들어가니까 더 좋다고 생각하실 수 있습니다.
"아마 일반 OS보다는 빠르지 않을까?"
뭐... 어떤 의미에서는 빠르다고 볼 수도 있겠지만, 정확한 답은 아닙니다.
일반 OS와 RTOS의 차이는 '응답성(응답속도)'에 차이가 있습니다.
그러니까 RTOS는 일을 주면 거기에 대한 반응이 빠르다는 말입니다.
"그럼 반응이 빠르면 당연히 속도도 빠를텐데 뭐가 잘못됐다는겁니까"
아직 이야기 안끝났습니다.
우리가 사용하는 일반 OS의 경우에는 범용적인 사용을 목적으로 만들어졌습니다.
컴퓨터를 켜기만 해도 프로세스가 수십 개가 됩니다.
내가 실행시키지도 않았는데 돌아가고 있는 프로세스도 있고요.
시키지도 않았는데도 하는 일이 많은게 일반 OS입니다.
그런데 RTOS는? 범용적인 OS가 아닙니다.
어떤 특수한 목적을 가지고 제한적인 영역에서 사용하는 OS입니다.
그래서 일반 OS에 비교하면 하는 일이 많지 않습니다.
예를 들어, 스마트폰에 들어가는 RTOS는 우리가 터치를 하거나 보내는 데이터가 없으면 일을 안합니다.
일을 안시키면 진짜로 아무것도 안하는게 RTOS입니다.
그래서 결과를 놓고 말한다면, 속도의 차이로 비교하는 것은 아무런 의미가 없습니다.
사실 속도를 결정짓는 것은 CPU의 성능이 절대적인 요소입니다.
이 둘의 차이는 응답성에서의 차이가 있다는 것 뿐입니다.
이걸 스케줄러의 관점에서 보겠습니다.
프로세스를 스케줄링할 때의 고려해야 하는 부분 중 '실행 시간'이 있습니다.
여기서 프로세스의 최소 실행 시간을 타임 슬라이스(Time Slice) 또는 퀀텀(Quantum)이라고 합니다.
이게 짧으면 즉각적으로 반응하기가 좋습니다.
하지만 컨텍스트 스위칭이 자주 발생하기 때문에 성능의 저하가 올 수 있습니다.
반대로 타임 슬라이스를 좀 길게 잡으면 컨텍스트 스위칭이 발생하는 빈도가 줄겠죠?
대신 반응 속도가 떨어진다는 단점이 있습니다.
그래서 일반 OS는 RTOS에 비해 타임 슬라이스를 길게 잡기 때문에 반응 속도가 느린 것입니다.
[Soft RTOS vs Hard RTOS]
이제 이 부분은 좀 가벼운 부록 정도로 생각하셔도 됩니다.
RTOS는 일반 OS와 그렇게 큰 차이가 있는 것도 아니었고 '반응속도가 좋다' 라고 마무리를 지었습니다.
이런 RTOS를 Soft RTOS라고 합니다.
우리가 살면서 접하는 대부분의 RTOS가 이런 것이라고 보면 됩니다.
그럼 Hard RTOS는 뭐냐?
전통적인 개념의 RTOS를 Hard RTOS라고 하는데, 여기서 중요한 것은 일반 OS보다 빠른 응답성이 아닙니다.
데드라인(Dead Line)을 지켜야하는 OS입니다.
여기서 말하는 데드라인이라는 것은 정말로 시간에 Critical한 상황에서 발생하는 것을 말합니다.
이를테면 자동차의 에어백 시스템을 예로 들 수 있겠습니다.
0.1초라도 늦게 터지면 운전자는 사망에 이르게 됩니다.
자동차의 에어백 시스템처럼 데드라인이 중요한 시스템에서 이 조건을 충족시킬 수 있는 OS를 Hard RTOS라고 합니다.
데드라인을 충족시키는 것은 단순히 CPU의 속도가 빠르다고 해서 해결되지 않습니다.
Hard RTOS의 스케줄러를 만들 때는 일반 OS와는 완전히 다른 스케줄링 알고리즘을 사용한다고 합니다.
그래서 Hard RTOS를 설계하는 것은 굉장히 어려운 일이라고 합니다.
[선점형(Preemptive) OS와 비선점형(Non-Preemptive) OS]
앞에서는 스케줄러와 응답성에 관련된 기준으로 일반 OS와 RTOS를 나눠봤습니다.
그럼 이번에는 선점형과 비선점형의 차이에 대해서도 정리해볼까 합니다.
여기도 마찬가지로 스케줄러의 관점에서 구분할 수 있습니다.
일단 간결하게 요약만 하자면 이렇게 정리됩니다.
비선점형 OS - 스케줄러가 많이 바쁘진 않다
선점형 OS - 스케줄러가 바쁘다
[비선점형 OS]
비선점형 OS는 쉽게 생각할 수 있게 예를 하나 들어보겠습니다.
좀 극단적인 예가 될텐데, 어떤 헬스장에는 벤치 프레스가 딱 하나만 있습니다.
이걸 이용할 수 있는 사람은 헬스장을 이용하는 사람이면 누구나 이용할 수 있죠.
헬스장 회원 한 명이 벤치 프레스를 이용하기 시작하면 본인이 하고 싶은만큼 계속 쓸 수 있습니다.
그런데 하나밖에 없는 만큼 다른 회원들도 이 운동기구를 쓰고 싶을겁니다.
그래서 운동을 하다가 다른 사람이 오면 눈치껏 비켜줘야하죠.
이게 비선점형 OS의 특징입니다.
위의 예를 좀 더 보태자면, 체육관 관장이나 운동선수가 와서 비키라고 해도 비켜야 할 의무가 없습니다.
즉, 현재 실행 중인 프로세스보다 우선순위가 높은 프로세스가 와도 실행 대상을 바로 바꾸지 않습니다.
실행중인 프로세스가 명시적으로 CPU를 양보하거나 I/O 작업으로 인해 Blocked 상태로 바뀌기 전까지는요.
제 발로 나오겠다고 하거나 I/O 작업으로 상태 변화를 하기 전까지 스케줄러는 가만히 보고만 있으면 되는겁니다.
그러다보니까 스케줄러가 할 일이 좀 적습니다.
그래서 비선점형 OS 환경에서는 상호작용을 필요로 하는 프로그램을 구현하는데 적합하지 않습니다.
프로그래머가 일일이 프로세스 상태를 고려해가면서 프로그래밍을 해야되거든요.
과거 Windows 3.x대가 도대체 언제적 비선점형 OS였다고 합니다.
[선점형 OS]
그럼 선점형은 스케줄러가 비선점형 OS와는 다르게 바쁘겠죠?
맞습니다!
선점형 OS는 현재 실행 중인 프로세스보다 높은 우선순위의 프로세스가 나타난다면?
스케줄러가 실행순서를 조정하는데 '적극적'으로 개입합니다.
우선순위가 높은 프로세스가 먼저 실행이 되는 것이죠.
그러다보니 비선점형 OS의 스케줄러에 비해서 굉장히 바쁩니다.
그리고 바쁘다는 말은?
둘 이상의 프로세스를 실행하는 멀티 프로세스 기반 OS에 적합한 방식이라는 말입니다.
그래서 비선점형 OS에 비해 프로그래머가 할 일도 많이 없습니다.
OS의 스케줄러가 다 해주니까요.
우리가 쓰고 있는 Windows도 그렇고, 유닉스나 리눅스도, RTOS도 선점형 OS입니다.
[우선순위(Priority) 스케줄링 알고리즘]
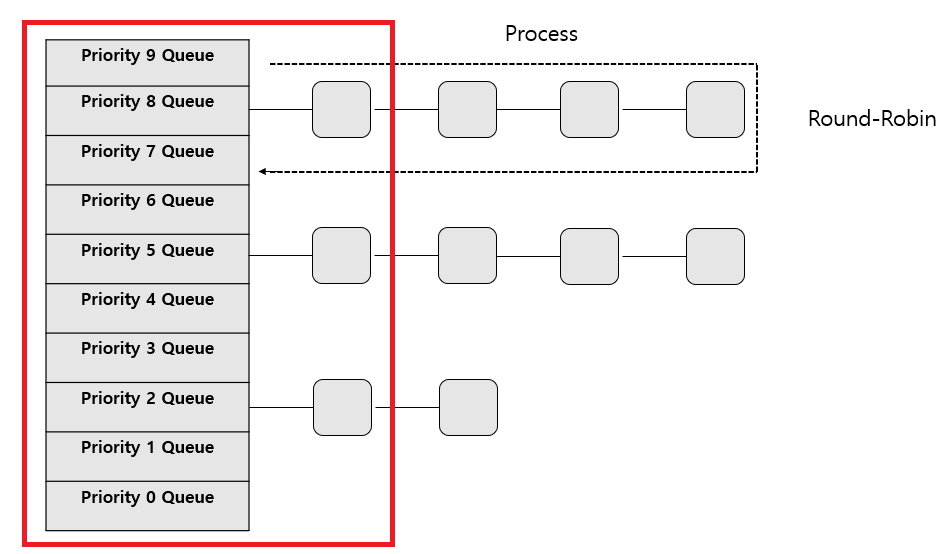
지금 우리가 공부하고 있는 Windows는 선점형 OS입니다.
그러면 당연히 선점형 OS에서 사용하는 스케줄링 알고리즘을 이해하는 것도 중요한 일입니다.
스케줄러가 어떻게 일을 하는지 알고 있어야죠.
Windows에서는 2가지의 스케줄링 알고리즘을 사용하고 있습니다.
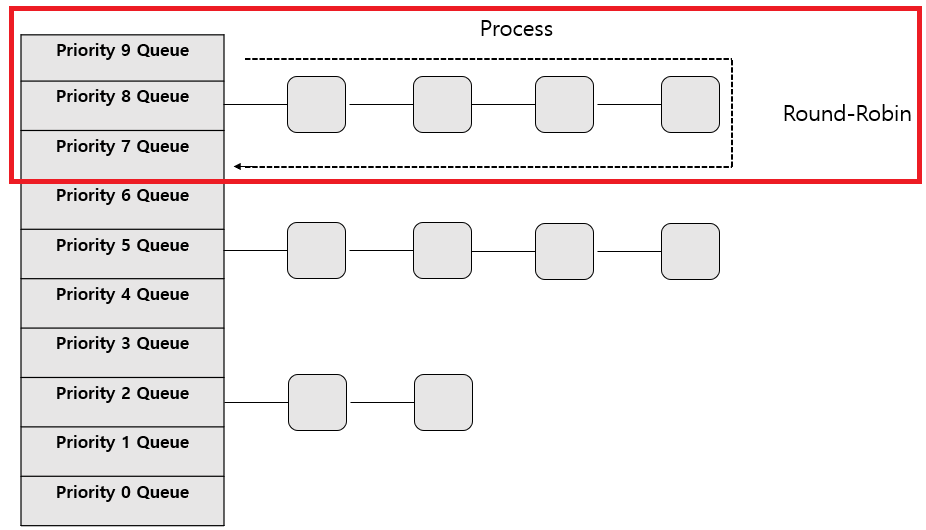
그 중 첫 번째로 알아볼 것은 '우선순위 스케줄링 알고리즘'입니다.
이 알고리즘의 키워드는 '특권'인데요.
말 그대로 프로세스마다 우선순위, 특권을 부여해서 우선순위가 높은 놈을 먼저 실행시키는 알고리즘입니다.
그러다보니 우선순위가 낮은 프로세스들은 기회조차도 못얻는 상황이 있습니다.
이런 상태에 빠지면 '기아(Starvation) 상태에 빠졌다'라고 합니다.
그럼 기아 상태에 빠진 프로세스는 평생 기아 상태에서만 있어야 하는가?
그건 절대 아닙니다.
대부분의 프로그램이, 거의 상당수의 시간을 I/O에 시간을 할애하게끔 되어있습니다.
다시 말하자면 우선순위가 높고 낮건간에 Blocked 상태가 된다는 겁니다.
그럼 우선순위가 높은 프로세스가 Blocked 상태일 때 우선순위가 낮은 프로세스가 실행될 수 있는거죠.
그래서 실제로 기아 상태에 빠지는 것은 매우 드문 일입니다.
[라운드 로빈(Round-Robin) 스케줄링 알고리즘]
라운드 로빈 방식은 아마 축구를 좋아하시는 분이면 바로 이해하실 수 있는 방식입니다.
월드컵이나 챔피언스 리그 예선이 이 방식을 사용합니다.
모든 팀들이 다 한 번씩 겨루고 승점이 가장 높은 두 팀이 본선으로 진출하게 되는 방식이죠.
여기서도 마찬가지입니다.
강팀이고 약팀이고 일단 예선에서는 다 '평등'하다고 보고 똑같이 붙게 하는 방식인거죠.
말 그대로 알고리즘의 키워드는 '평등'인데요.
앞에 말이 좀 빠져있습니다.'같은 우선순위의 프로세스 간의 평등'입니다.
만약 같은 우선순위의 프로세스가 여러 개가 실행이 되어야 한다면, 어떻게 해결해야할까요?
간단합니다. 형평성을 유지하기 위해서 시간을 딱 정해놓고 돌아가면서 실행하면 됩니다.
여기서 아까 이야기했던 타임 슬라이스 개념이 여기에 적용됩니다.
정해진 타임 슬라이스만큼 실행시키고, CPU를 돌아가면서 쓰는 알고리즘입니다.
그래서 타임 슬라이스를 어느 정도로 정하느냐에 따라서 OS의 성격이 달라지기도 합니다.
위에서 이야기했던 것처럼 타임 슬라이스를 짧게 잡으면 반응 속도는 빨라집니다.
하지만 컨텍스트 스위칭이 빈번하게 발생하므로 성능의 저하가 있을 수 있죠.
반대로 타임 슬라이스를 길게 잡으면 반응 속도는 느려집니다.
대신 컨텍스트 스위칭에 의한 성능 저하는 상대적으로 떨어지게 되는 것이고요.
[스케줄링 알고리즘에 의해서 스케줄링이 진행되는 시점]
앞서 설명했던 두 알고리즘은 Windows에서 혼용해서 사용하고 있습니다.
그리고 지금 사용하고 있는 대부분의 운영체제에서도 동일한 방식을 채택하고 있습니다.
이번에는 앞서 소개했던 스케줄링 알고리즘에 의해서 스케줄링이 진행되는 시점을 한 번 알아보겠습니다.
스케줄러가 어떤 알고리즘을 사용하는 지 이해하는 것이 중요하다고 했습니다.
그러면 이 알고리즘을 적용하는 시점은 언제인지 아는 것도 당연히 중요합니다.
우선 세 가지의 관점에서 생각해볼 수 있습니다.
가장 먼저 라운드 로빈 스케줄링 알고리즘 측면에서 고려를 해봅시다.
같은 우선 순위의 프로세스들끼리 정해진 시간 동안은 Running 상태가 됩니다.
그리고 그 시간이 다 끝나면 Ready 상태로 돌아가야 하죠.
그 때 스케줄러가 동작해야 다음 프로세스가 Running 상태가 될 수 있습니다.
다시 말하자면 정해진 시간, 프로세스의 실행 시간인 매 타임 슬라이스마다 스케줄러가 실행되어야 합니다.
이제 두 번째로는 우선순위 방식 스케줄링 알고리즘 측면에서 생각해봅시다.
우선순위가 높은 프로세스는 반드시 먼저 실행되어야 합니다.
그래서 새로운 프로세스가 생성될 때 우선순위를 확인해야하고, 높다면 실행 순서를 바꿔줘야 합니다.
반대로 프로세스가 실행을 마치고 소멸하게 되면 그 다음으로 우선순위가 같거나 높은 프로세스를 실행시켜야 합니다.
즉, 프로세스가 생성 및 소멸될 때마다 스케줄러가 실행되어야 합니다.
마지막으로는 프로세스가 블로킹된 상황(Blocked 상태에 들어간 상황)에서 생각해봅시다.
현재 실행 중인 프로세스가 블로킹 상태가 되면 다른 프로세스가 대신 실행됩니다.
그러면 현재 프로세스 다음으로 우선순위가 같거나 높은 프로세스를 실행시켜아합니다.
이때도 스케줄러가 실행되어야만 다음 프로세스가 선정되고 실행이 될 수 있겠죠.
그래서 현재 실행 중인 프로세스가 블로킹 상태에 높일 때마다 스케줄러가 실행되어야 합니다.
요약하면 다음과 같은 세 가지 경우에 스케줄러가 동작하게 됩니다.
1) 매 타임 슬라이스(Time Slice)마다
2) 프로세스가 생성 및 소멸될 때마다
3) 현재 실행 중인 프로세스가 블로킹 상태에 놓일 때마다
무조건 외우기보다는 위의 상황을 생각하면서 이해를 하시는게 좋습니다.
그리고 이 세 가지 경우를 놓고 봤을 때 더 생각해볼 수 있는 것이 있습니다.
왜 이런 경우에 스케줄러가 실행되게 했을까요?
"스케줄러 또한 프로세스이기 때문"
이게 무슨 말인지 한 번 보겠습니다.
우선 1번 케이스와 2, 3번 케이스를 묶어서 나눠보겠습니다.
1번 케이스를 고려하면 타임 슬라이스를 짧게 잡은 경우에는 컨텍스트 스위칭이 빈번하게 일어나게 됩니다.
하지만 타임 슬라이스가 짧은 만큼 스케줄러가 빈번하게 동작하기 때문에 2, 3번 케이스는 덜 일어날 수 있습니다.
반대로 타임 슬라이스를 길게 잡은 경우에는 컨텍스트 스위칭이 빈번하게 일어나진 않습니다.
대신 프로세스가 실행되는 시간이 상대적으로 길어지게 됩니다.
그래서 그 실행되는 동안 다른 프로세스가 생성될 수도 있고, 실행 중인 프로세스가 블로킹 상황에 빠질 수도 있습니다.
이 경우에는 1번 케이스는 덜 일어나는 반면에 2, 3번 케이스가 더 빈번하게 발생하게 되는 것입니다.
아까 "스케줄러 또한 프로세스"라고 했습니다.
마찬가지로 스케줄러 역시 프로세스고, 프로세스를 자주 호출한다는 것은 CPU에게 부담을 주는 것입니다.
그래서 최소한으로 스케줄러를 동작시키기 위해서 위와 같은 경우를 둔 것입니다.
이는 성능적인 측면을 고려한 것이라고 볼 수 있습니다.
[Priority Inversion]
이번에 다룰 내용은 영어 단어 뜻 그대로 우선순위가 뒤바뀌는 현상을 말합니다.
학부 운영체제에서 중간고사 문제로도 나올만큼 저는 본 기억이 없습니다 학문적으로 중요한 내용입니다.
OS를 개발자가 고려해야 할 사항인데, 경우에 따라서는 개발자들이 고려해야 하는 경우도 있습니다.
프로세스 A > 프로세스 B > 프로세스 C
현재 프로세스의 우선순위는 다음과 같습니다.
그리고 프로세스 A와 C는 IPC를 통해 연결이 되어있는 상황입니다.
프로세스 A는 현재 실행 중에 있고, B와 C는 실행이 되기를 기다리고 있습니다.
그런데 프로세스 A가 작업을 멈추게 됩니다.
프로세스 C가 계산한 값을 토대로 작업을 이어서 진행해야 하는데, 프로세스 C의 값이 오질 않은 것입니다.
프로세스 A는 프로세스 C가 계산한 값을 받기 위해 Blocked 상태로 들어가면서 프로세스 C에게 기회를 주려고 합니다.
그런데 이게 웬걸?
프로세스 B가 그 자리를 꿰차고 들어가서 나오질 않는겁니다.
프로세스 A의 입장에서는 C가 실행될 것을 기대하고 Blocked 상태가 되었는데 말이죠.
그래서 프로세스 A는 너무 억울하다며 이렇게 말합니다.
"이건 아니야! 우선순위가 바뀐거잖아!"
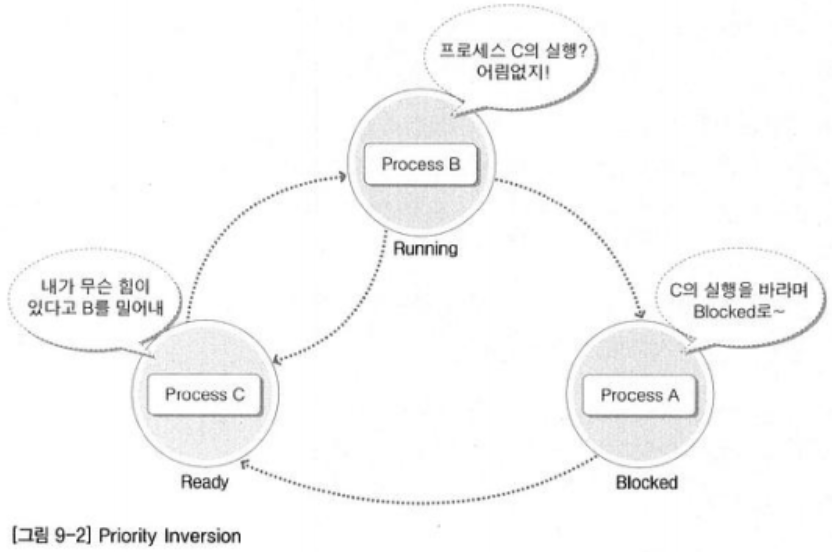
실제로는 우선순위가 바뀐 일은 없었습니다.
그렇지만 결과적으로는 프로세스 B가 가장 우선순위가 높은 것처럼 되었습니다.
그리고 프로세스 A가 가장 우선순위가 낮아진 꼴이 된겁니다.
이와 같은 현상을 '우선순위 역전(Priority Inversion)'이라고 합니다.
해결하는 방법은 이론적으로는 두 가지가 있는데, 실제로 사용되는 방법은 상속을 하는 것입니다.
프로세스 A가 Blocked 상태로 바로 빠지는 것이 아니라 프로세스 C에게 우선순위를 위임하는 것입니다.
그러면 B보다 C의 우선순위가 높아지게 되고, C가 먼저 실행되게 됩니다.
실제 이론적으로는 PIP, PCP라는 방식이 있으니 나중에 찾아보시면 더 도움이 될 것 같습니다.
[Windows 프로세스 우선순위]
마지막으로는 Windows에서 사용하는 우선순위 계층을 확인해보겠습니다.
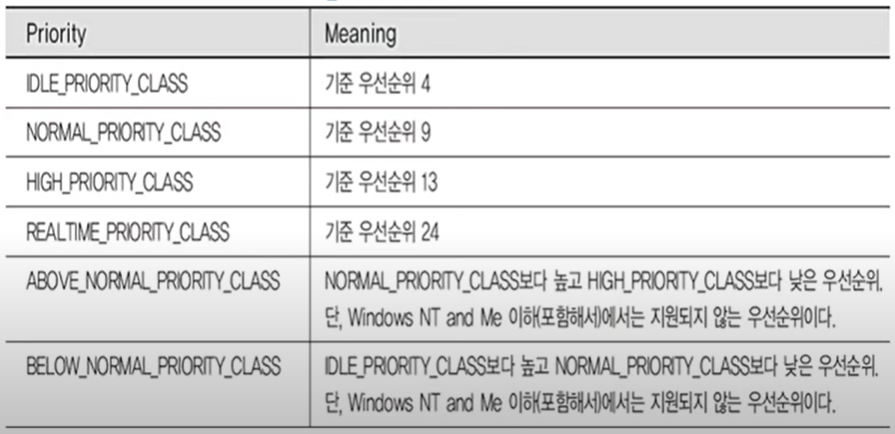
그리고 간단하게나마 소스코드 예제를 통해서 이렇게 사용한다는 것을 알아두시면 됩니다.
[ABOVE_NORMAL_PRIORITY_CLASS.cpp]
/*
* Windows System Programming - 스케줄링 알고리즘과 우선순위
* 파일명: ABOVE_NORMAL_PRIORITY_CLASS.cpp
* 파일 버전: 0.1
* 작성자: Sevenshards
* 작성 일자: 2023-12-07
* 이전 버전 작성 일자:
* 버전 내용: 우선순위를 적용한 스케줄링 알고리즘이 적용되는 것을 확인하는 예제
* 이전 버전 내용:
*/
#include <stdio.h>
#include <tchar.h>
#include <Windows.h>
int _tmain(int argc, TCHAR* argv[])
{
// 우선순위 NORMAL_PRIORITY_CLASS를 부여할 자식 프로세스
STARTUPINFO si_Normal = { 0, };
PROCESS_INFORMATION pi_Normal = { 0, };
TCHAR cmdNormal[] = _T("NORMAL_PRIORITY_CLASS.exe");
// 우선순위 BELOW_NORMAL_PRIORITY_CLASS를 부여할 자식 프로세스
STARTUPINFO si_Below = { 0, };
PROCESS_INFORMATION pi_Below = { 0, };
TCHAR cmdBelow[] = _T("BELOW_NORMAL_PRIORITY_CLASS.exe");
si_Normal.cb = sizeof(si_Normal);
si_Below.cb = sizeof(si_Below);
SetPriorityClass(GetCurrentProcess(), ABOVE_NORMAL_PRIORITY_CLASS);
// 자식 프로세스 생성
CreateProcess(
NULL,cmdNormal, NULL, NULL, TRUE,
0, NULL, NULL, &si_Normal, &pi_Normal);
CreateProcess(
NULL, cmdBelow, NULL, NULL, TRUE,
0, NULL, NULL, &si_Below, &pi_Below);
while (1)
{
for (DWORD i = 0; i < 10000; i++)
for (DWORD i = 0; i < 10000; i++); // Busy Waiting
//Sleep(10);
_fputts(_T("ABOVE_NORMAL_PRIORITY_CLASS Process\n"), stdout);
}
return 0;
}
[NORMAL_PRIORITY_CLASS.cpp]
/*
* Windows System Programming - 스케줄링 알고리즘과 우선순위
* 파일명: NORMAL_PRIORITY_CLASS.cpp
* 파일 버전: 0.1
* 작성자: Sevenshards
* 작성 일자: 2023-12-07
* 이전 버전 작성 일자:
* 버전 내용: 우선순위를 적용한 스케줄링 알고리즘이 적용되는 것을 확인하는 예제
* 이전 버전 내용:
*/
#include <stdio.h>
#include <tchar.h>
#include <Windows.h>
int _tmain(int argc, TCHAR* argv[])
{
SetPriorityClass(GetCurrentProcess(), NORMAL_PRIORITY_CLASS);
while (1)
{
for (DWORD i = 0; i < 10000; i++)
for (DWORD i = 0; i < 10000; i++); // Busy Waiting
//Sleep(10);
_fputts(_T("NORMAL_PRIORITY_CLASS Process\n"), stdout);
}
return 0;
}
[BELOW_NORMAL_PRIORITY_CLASS.cpp]
/*
* Windows System Programming - 스케줄링 알고리즘과 우선순위
* 파일명: BELOW_NORMAL_PRIORITY_CLASS.cpp
* 파일 버전: 0.1
* 작성자: Sevenshards
* 작성 일자: 2023-12-07
* 이전 버전 작성 일자:
* 버전 내용: 우선순위를 적용한 스케줄링 알고리즘이 적용되는 것을 확인하는 예제
* 이전 버전 내용:
*/
#include <stdio.h>
#include <tchar.h>
#include <Windows.h>
int _tmain(int argc, TCHAR* argv[])
{
SetPriorityClass(GetCurrentProcess(), BELOW_NORMAL_PRIORITY_CLASS);
while (1)
{
for (DWORD i = 0; i < 10000; i++)
for (DWORD i = 0; i < 10000; i++); // Busy Waiting
//Sleep(10);
_fputts(_T("BELOW_PRIORITY_CLASS Process\n"), stdout);
}
return 0;
}
어차피 지금 대부분 쓰시는 PC의 환경이 싱글코어인 분들은 없다고 생각합니다.
멀티코어 환경에서 실행하면 예상했던 우선순위 결과대로 절대 나오질 않습니다.
그래서 여기는 크게 중요하다고 하질 않았습니다.
실제로 우선순위에 대해서 정확하게 따지려면 쓰레드까지 가야 합니다.
지금은 앞에서 소개한 내용들이 더 중요하기 때문에 지금은 이런게 있다 정도로 이해하면 좋습니다.
<스케줄링 알고리즘과 우선순위>
[공부 했던 것을 되짚어보며]
책으로 치면 어느덧 2장의 끝에 왔습니다.
지금까지 컴퓨터 구조에 대한 이야기도 했었고, 프로세스에 대한 이야기도 했었죠.
그리고 커널 오브젝트와 핸들, 핸들 테이블에 대한 이야기도 했습니다.
특히 이 커널 오브젝트라는 개념이 뒤에 가서도 굉장히 많이 언급이 될겁니다.
저는 4장 이전까지 공부를 하고 복습 차원에서 글을 작성하고 있습니다.
여기서 다뤘던 커널 오브젝트와 핸들부터 핸들 테이블까지의 개념은 잘 정리해두시길 바랍니다.
뒤에 가서 이 개념을 모르면 진짜 11챕터까지 가서 7~8챕터를 오락가락하게 됩니다.
개인적인 잡소리가 더 길어지면 안되니까 공부했던 것을 정리해보겠습니다.
[프로세스의 스케줄링(Scheduling]
우리가 쉽게 접하는 대부분의 운영체제는 멀티 프로세스 기반의 운영체제입니다.
물론 운영체제마다 제공하는 시스템 함수들은 조금씩 차이가 있습니다.
하지만 목적은 같습니다.
우리가 앞서 배워왔던 프로세스 생성과 소멸에 대한 시스템 함수를 유닉스나 리눅스에서도 지원합니다.
프로세스간 통신 기법도 똑같이 지원합니다.
결과적으로는 여기나 거기나 프로세스라는 개념은 중요하다는 것입니다.
이제 본론으로 넘어오겠습니다.
프로세스는 실행 중인 하나의 프로그램입니다.
그리고 하나의 프로그램이 실행되기 위해서는 하나의 CPU(정확히는 코어)가 필요합니다.
프로세스 수만큼 CPU가 있으면 정말 좋겠죠.
그런데 우리가 쓰는 PC에는 CPU가 몇개인가요? 단 하나입니다.
요즘에는 CPU의 코어수가 많아져서 하나로도 충분한 세상이긴 합니다.
두 자릿수의 코어가 기본인 세상이잖아요.
(싱글, 듀얼코어 CPU를 쓰면 천연기념물(?)이라고 봐야 할 수준)
그런데 우리가 실제로 실행하는 프로그램의 갯수는 얼마나 될까요?
20개는 넘어가는 분들이 많으실겁니다. 코어 갯수는 거뜬히 넘기는거죠.
이번에 다룰 주제는 '스케줄러(Scheduler)'라는 놈입니다.
이전 글에서도 프로세스 스케줄링이 왜 필요한지, 프로세스의 상태도 공부를 했었죠.
https://sevenshards.tistory.com/43
[Windows System Programming] 프로세스의 생성과 소멸
[프로세스의 이해] 현재 운영체제는 "멀티 프로세스(Multi-Process) 운영체제"라고 한다. 쉽게 말하면 "프로세스라는 것이 여러개 존재할 수 있는 운영체제"를 말한다. 여기서 프로세스라는 것을 뭘
sevenshards.tistory.com
기억이 안나신다면 다시 보고 오는 것도 좋습니다.
프로세스가 CPU에 골고루 할당되기 위해서는 프로세스 스케줄링이 필요합니다.
그리고 이 일을 하는 것은 멀티 프로세스를 지원하는 운영체제에서 담당하게 됩니다.
그 중에서도 '스케줄러'라는 놈이 이 일을 하는 것입니다.
[일반 OS와 리얼타임(Real Time) OS의 차이점]
스케줄러 이야기를 한다면서, 운영체제의 차이점?
뭔 뜬금없는 주제인가 싶으실겁니다.
결론만 먼저 짚고 넘어간다면, 이 둘은 스케줄러의 차이가 있습니다.
우선 일반 OS는 우리가 사용하고 있는 Windows나 리눅스 같은 것들이 있겠네요.
그럼 Real Time OS(줄여서 RTOS)는 뭐냐?
일단 앞에 실시간이라는 단어가 들어가니까 더 좋다고 생각하실 수 있습니다.
"아마 일반 OS보다는 빠르지 않을까?"
뭐... 어떤 의미에서는 빠르다고 볼 수도 있겠지만, 정확한 답은 아닙니다.
일반 OS와 RTOS의 차이는 '응답성(응답속도)'에 차이가 있습니다.
그러니까 RTOS는 일을 주면 거기에 대한 반응이 빠르다는 말입니다.
"그럼 반응이 빠르면 당연히 속도도 빠를텐데 뭐가 잘못됐다는겁니까"
아직 이야기 안끝났습니다.
우리가 사용하는 일반 OS의 경우에는 범용적인 사용을 목적으로 만들어졌습니다.
컴퓨터를 켜기만 해도 프로세스가 수십 개가 됩니다.
내가 실행시키지도 않았는데 돌아가고 있는 프로세스도 있고요.
시키지도 않았는데도 하는 일이 많은게 일반 OS입니다.
그런데 RTOS는? 범용적인 OS가 아닙니다.
어떤 특수한 목적을 가지고 제한적인 영역에서 사용하는 OS입니다.
그래서 일반 OS에 비교하면 하는 일이 많지 않습니다.
예를 들어, 스마트폰에 들어가는 RTOS는 우리가 터치를 하거나 보내는 데이터가 없으면 일을 안합니다.
일을 안시키면 진짜로 아무것도 안하는게 RTOS입니다.
그래서 결과를 놓고 말한다면, 속도의 차이로 비교하는 것은 아무런 의미가 없습니다.
사실 속도를 결정짓는 것은 CPU의 성능이 절대적인 요소입니다.
이 둘의 차이는 응답성에서의 차이가 있다는 것 뿐입니다.
이걸 스케줄러의 관점에서 보겠습니다.
프로세스를 스케줄링할 때의 고려해야 하는 부분 중 '실행 시간'이 있습니다.
여기서 프로세스의 최소 실행 시간을 타임 슬라이스(Time Slice) 또는 퀀텀(Quantum)이라고 합니다.
이게 짧으면 즉각적으로 반응하기가 좋습니다.
하지만 컨텍스트 스위칭이 자주 발생하기 때문에 성능의 저하가 올 수 있습니다.
반대로 타임 슬라이스를 좀 길게 잡으면 컨텍스트 스위칭이 발생하는 빈도가 줄겠죠?
대신 반응 속도가 떨어진다는 단점이 있습니다.
그래서 일반 OS는 RTOS에 비해 타임 슬라이스를 길게 잡기 때문에 반응 속도가 느린 것입니다.
[Soft RTOS vs Hard RTOS]
이제 이 부분은 좀 가벼운 부록 정도로 생각하셔도 됩니다.
RTOS는 일반 OS와 그렇게 큰 차이가 있는 것도 아니었고 '반응속도가 좋다' 라고 마무리를 지었습니다.
이런 RTOS를 Soft RTOS라고 합니다.
우리가 살면서 접하는 대부분의 RTOS가 이런 것이라고 보면 됩니다.
그럼 Hard RTOS는 뭐냐?
전통적인 개념의 RTOS를 Hard RTOS라고 하는데, 여기서 중요한 것은 일반 OS보다 빠른 응답성이 아닙니다.
데드라인(Dead Line)을 지켜야하는 OS입니다.
여기서 말하는 데드라인이라는 것은 정말로 시간에 Critical한 상황에서 발생하는 것을 말합니다.
이를테면 자동차의 에어백 시스템을 예로 들 수 있겠습니다.
0.1초라도 늦게 터지면 운전자는 사망에 이르게 됩니다.
자동차의 에어백 시스템처럼 데드라인이 중요한 시스템에서 이 조건을 충족시킬 수 있는 OS를 Hard RTOS라고 합니다.
데드라인을 충족시키는 것은 단순히 CPU의 속도가 빠르다고 해서 해결되지 않습니다.
Hard RTOS의 스케줄러를 만들 때는 일반 OS와는 완전히 다른 스케줄링 알고리즘을 사용한다고 합니다.
그래서 Hard RTOS를 설계하는 것은 굉장히 어려운 일이라고 합니다.
[선점형(Preemptive) OS와 비선점형(Non-Preemptive) OS]
앞에서는 스케줄러와 응답성에 관련된 기준으로 일반 OS와 RTOS를 나눠봤습니다.
그럼 이번에는 선점형과 비선점형의 차이에 대해서도 정리해볼까 합니다.
여기도 마찬가지로 스케줄러의 관점에서 구분할 수 있습니다.
일단 간결하게 요약만 하자면 이렇게 정리됩니다.
비선점형 OS - 스케줄러가 많이 바쁘진 않다
선점형 OS - 스케줄러가 바쁘다
[비선점형 OS]
비선점형 OS는 쉽게 생각할 수 있게 예를 하나 들어보겠습니다.
좀 극단적인 예가 될텐데, 어떤 헬스장에는 벤치 프레스가 딱 하나만 있습니다.
이걸 이용할 수 있는 사람은 헬스장을 이용하는 사람이면 누구나 이용할 수 있죠.
헬스장 회원 한 명이 벤치 프레스를 이용하기 시작하면 본인이 하고 싶은만큼 계속 쓸 수 있습니다.
그런데 하나밖에 없는 만큼 다른 회원들도 이 운동기구를 쓰고 싶을겁니다.
그래서 운동을 하다가 다른 사람이 오면 눈치껏 비켜줘야하죠.
이게 비선점형 OS의 특징입니다.
위의 예를 좀 더 보태자면, 체육관 관장이나 운동선수가 와서 비키라고 해도 비켜야 할 의무가 없습니다.
즉, 현재 실행 중인 프로세스보다 우선순위가 높은 프로세스가 와도 실행 대상을 바로 바꾸지 않습니다.
실행중인 프로세스가 명시적으로 CPU를 양보하거나 I/O 작업으로 인해 Blocked 상태로 바뀌기 전까지는요.
제 발로 나오겠다고 하거나 I/O 작업으로 상태 변화를 하기 전까지 스케줄러는 가만히 보고만 있으면 되는겁니다.
그러다보니까 스케줄러가 할 일이 좀 적습니다.
그래서 비선점형 OS 환경에서는 상호작용을 필요로 하는 프로그램을 구현하는데 적합하지 않습니다.
프로그래머가 일일이 프로세스 상태를 고려해가면서 프로그래밍을 해야되거든요.
과거 Windows 3.x대가 도대체 언제적 비선점형 OS였다고 합니다.
[선점형 OS]
그럼 선점형은 스케줄러가 비선점형 OS와는 다르게 바쁘겠죠?
맞습니다!
선점형 OS는 현재 실행 중인 프로세스보다 높은 우선순위의 프로세스가 나타난다면?
스케줄러가 실행순서를 조정하는데 '적극적'으로 개입합니다.
우선순위가 높은 프로세스가 먼저 실행이 되는 것이죠.
그러다보니 비선점형 OS의 스케줄러에 비해서 굉장히 바쁩니다.
그리고 바쁘다는 말은?
둘 이상의 프로세스를 실행하는 멀티 프로세스 기반 OS에 적합한 방식이라는 말입니다.
그래서 비선점형 OS에 비해 프로그래머가 할 일도 많이 없습니다.
OS의 스케줄러가 다 해주니까요.
우리가 쓰고 있는 Windows도 그렇고, 유닉스나 리눅스도, RTOS도 선점형 OS입니다.
[우선순위(Priority) 스케줄링 알고리즘]
지금 우리가 공부하고 있는 Windows는 선점형 OS입니다.
그러면 당연히 선점형 OS에서 사용하는 스케줄링 알고리즘을 이해하는 것도 중요한 일입니다.
스케줄러가 어떻게 일을 하는지 알고 있어야죠.
Windows에서는 2가지의 스케줄링 알고리즘을 사용하고 있습니다.
그 중 첫 번째로 알아볼 것은 '우선순위 스케줄링 알고리즘'입니다.
이 알고리즘의 키워드는 '특권'인데요.
말 그대로 프로세스마다 우선순위, 특권을 부여해서 우선순위가 높은 놈을 먼저 실행시키는 알고리즘입니다.
그러다보니 우선순위가 낮은 프로세스들은 기회조차도 못얻는 상황이 있습니다.
이런 상태에 빠지면 '기아(Starvation) 상태에 빠졌다'라고 합니다.
그럼 기아 상태에 빠진 프로세스는 평생 기아 상태에서만 있어야 하는가?
그건 절대 아닙니다.
대부분의 프로그램이, 거의 상당수의 시간을 I/O에 시간을 할애하게끔 되어있습니다.
다시 말하자면 우선순위가 높고 낮건간에 Blocked 상태가 된다는 겁니다.
그럼 우선순위가 높은 프로세스가 Blocked 상태일 때 우선순위가 낮은 프로세스가 실행될 수 있는거죠.
그래서 실제로 기아 상태에 빠지는 것은 매우 드문 일입니다.
[라운드 로빈(Round-Robin) 스케줄링 알고리즘]
라운드 로빈 방식은 아마 축구를 좋아하시는 분이면 바로 이해하실 수 있는 방식입니다.
월드컵이나 챔피언스 리그 예선이 이 방식을 사용합니다.
모든 팀들이 다 한 번씩 겨루고 승점이 가장 높은 두 팀이 본선으로 진출하게 되는 방식이죠.
여기서도 마찬가지입니다.
강팀이고 약팀이고 일단 예선에서는 다 '평등'하다고 보고 똑같이 붙게 하는 방식인거죠.
말 그대로 알고리즘의 키워드는 '평등'인데요.
앞에 말이 좀 빠져있습니다.'같은 우선순위의 프로세스 간의 평등'입니다.
만약 같은 우선순위의 프로세스가 여러 개가 실행이 되어야 한다면, 어떻게 해결해야할까요?
간단합니다. 형평성을 유지하기 위해서 시간을 딱 정해놓고 돌아가면서 실행하면 됩니다.
여기서 아까 이야기했던 타임 슬라이스 개념이 여기에 적용됩니다.
정해진 타임 슬라이스만큼 실행시키고, CPU를 돌아가면서 쓰는 알고리즘입니다.
그래서 타임 슬라이스를 어느 정도로 정하느냐에 따라서 OS의 성격이 달라지기도 합니다.
위에서 이야기했던 것처럼 타임 슬라이스를 짧게 잡으면 반응 속도는 빨라집니다.
하지만 컨텍스트 스위칭이 빈번하게 발생하므로 성능의 저하가 있을 수 있죠.
반대로 타임 슬라이스를 길게 잡으면 반응 속도는 느려집니다.
대신 컨텍스트 스위칭에 의한 성능 저하는 상대적으로 떨어지게 되는 것이고요.
[스케줄링 알고리즘에 의해서 스케줄링이 진행되는 시점]
앞서 설명했던 두 알고리즘은 Windows에서 혼용해서 사용하고 있습니다.
그리고 지금 사용하고 있는 대부분의 운영체제에서도 동일한 방식을 채택하고 있습니다.
이번에는 앞서 소개했던 스케줄링 알고리즘에 의해서 스케줄링이 진행되는 시점을 한 번 알아보겠습니다.
스케줄러가 어떤 알고리즘을 사용하는 지 이해하는 것이 중요하다고 했습니다.
그러면 이 알고리즘을 적용하는 시점은 언제인지 아는 것도 당연히 중요합니다.
우선 세 가지의 관점에서 생각해볼 수 있습니다.
가장 먼저 라운드 로빈 스케줄링 알고리즘 측면에서 고려를 해봅시다.
같은 우선 순위의 프로세스들끼리 정해진 시간 동안은 Running 상태가 됩니다.
그리고 그 시간이 다 끝나면 Ready 상태로 돌아가야 하죠.
그 때 스케줄러가 동작해야 다음 프로세스가 Running 상태가 될 수 있습니다.
다시 말하자면 정해진 시간, 프로세스의 실행 시간인 매 타임 슬라이스마다 스케줄러가 실행되어야 합니다.
이제 두 번째로는 우선순위 방식 스케줄링 알고리즘 측면에서 생각해봅시다.
우선순위가 높은 프로세스는 반드시 먼저 실행되어야 합니다.
그래서 새로운 프로세스가 생성될 때 우선순위를 확인해야하고, 높다면 실행 순서를 바꿔줘야 합니다.
반대로 프로세스가 실행을 마치고 소멸하게 되면 그 다음으로 우선순위가 같거나 높은 프로세스를 실행시켜야 합니다.
즉, 프로세스가 생성 및 소멸될 때마다 스케줄러가 실행되어야 합니다.
마지막으로는 프로세스가 블로킹된 상황(Blocked 상태에 들어간 상황)에서 생각해봅시다.
현재 실행 중인 프로세스가 블로킹 상태가 되면 다른 프로세스가 대신 실행됩니다.
그러면 현재 프로세스 다음으로 우선순위가 같거나 높은 프로세스를 실행시켜아합니다.
이때도 스케줄러가 실행되어야만 다음 프로세스가 선정되고 실행이 될 수 있겠죠.
그래서 현재 실행 중인 프로세스가 블로킹 상태에 높일 때마다 스케줄러가 실행되어야 합니다.
요약하면 다음과 같은 세 가지 경우에 스케줄러가 동작하게 됩니다.
1) 매 타임 슬라이스(Time Slice)마다
2) 프로세스가 생성 및 소멸될 때마다
3) 현재 실행 중인 프로세스가 블로킹 상태에 놓일 때마다
무조건 외우기보다는 위의 상황을 생각하면서 이해를 하시는게 좋습니다.
그리고 이 세 가지 경우를 놓고 봤을 때 더 생각해볼 수 있는 것이 있습니다.
왜 이런 경우에 스케줄러가 실행되게 했을까요?
"스케줄러 또한 프로세스이기 때문"
이게 무슨 말인지 한 번 보겠습니다.
우선 1번 케이스와 2, 3번 케이스를 묶어서 나눠보겠습니다.
1번 케이스를 고려하면 타임 슬라이스를 짧게 잡은 경우에는 컨텍스트 스위칭이 빈번하게 일어나게 됩니다.
하지만 타임 슬라이스가 짧은 만큼 스케줄러가 빈번하게 동작하기 때문에 2, 3번 케이스는 덜 일어날 수 있습니다.
반대로 타임 슬라이스를 길게 잡은 경우에는 컨텍스트 스위칭이 빈번하게 일어나진 않습니다.
대신 프로세스가 실행되는 시간이 상대적으로 길어지게 됩니다.
그래서 그 실행되는 동안 다른 프로세스가 생성될 수도 있고, 실행 중인 프로세스가 블로킹 상황에 빠질 수도 있습니다.
이 경우에는 1번 케이스는 덜 일어나는 반면에 2, 3번 케이스가 더 빈번하게 발생하게 되는 것입니다.
아까 "스케줄러 또한 프로세스"라고 했습니다.
마찬가지로 스케줄러 역시 프로세스고, 프로세스를 자주 호출한다는 것은 CPU에게 부담을 주는 것입니다.
그래서 최소한으로 스케줄러를 동작시키기 위해서 위와 같은 경우를 둔 것입니다.
이는 성능적인 측면을 고려한 것이라고 볼 수 있습니다.
[Priority Inversion]
이번에 다룰 내용은 영어 단어 뜻 그대로 우선순위가 뒤바뀌는 현상을 말합니다.
학부 운영체제에서 중간고사 문제로도 나올만큼 저는 본 기억이 없습니다 학문적으로 중요한 내용입니다.
OS를 개발자가 고려해야 할 사항인데, 경우에 따라서는 개발자들이 고려해야 하는 경우도 있습니다.
프로세스 A > 프로세스 B > 프로세스 C
현재 프로세스의 우선순위는 다음과 같습니다.
그리고 프로세스 A와 C는 IPC를 통해 연결이 되어있는 상황입니다.
프로세스 A는 현재 실행 중에 있고, B와 C는 실행이 되기를 기다리고 있습니다.
그런데 프로세스 A가 작업을 멈추게 됩니다.
프로세스 C가 계산한 값을 토대로 작업을 이어서 진행해야 하는데, 프로세스 C의 값이 오질 않은 것입니다.
프로세스 A는 프로세스 C가 계산한 값을 받기 위해 Blocked 상태로 들어가면서 프로세스 C에게 기회를 주려고 합니다.
그런데 이게 웬걸?
프로세스 B가 그 자리를 꿰차고 들어가서 나오질 않는겁니다.
프로세스 A의 입장에서는 C가 실행될 것을 기대하고 Blocked 상태가 되었는데 말이죠.
그래서 프로세스 A는 너무 억울하다며 이렇게 말합니다.
"이건 아니야! 우선순위가 바뀐거잖아!"
실제로는 우선순위가 바뀐 일은 없었습니다.
그렇지만 결과적으로는 프로세스 B가 가장 우선순위가 높은 것처럼 되었습니다.
그리고 프로세스 A가 가장 우선순위가 낮아진 꼴이 된겁니다.
이와 같은 현상을 '우선순위 역전(Priority Inversion)'이라고 합니다.
해결하는 방법은 이론적으로는 두 가지가 있는데, 실제로 사용되는 방법은 상속을 하는 것입니다.
프로세스 A가 Blocked 상태로 바로 빠지는 것이 아니라 프로세스 C에게 우선순위를 위임하는 것입니다.
그러면 B보다 C의 우선순위가 높아지게 되고, C가 먼저 실행되게 됩니다.
실제 이론적으로는 PIP, PCP라는 방식이 있으니 나중에 찾아보시면 더 도움이 될 것 같습니다.
[Windows 프로세스 우선순위]
마지막으로는 Windows에서 사용하는 우선순위 계층을 확인해보겠습니다.
그리고 간단하게나마 소스코드 예제를 통해서 이렇게 사용한다는 것을 알아두시면 됩니다.
[ABOVE_NORMAL_PRIORITY_CLASS.cpp]
/*
* Windows System Programming - 스케줄링 알고리즘과 우선순위
* 파일명: ABOVE_NORMAL_PRIORITY_CLASS.cpp
* 파일 버전: 0.1
* 작성자: Sevenshards
* 작성 일자: 2023-12-07
* 이전 버전 작성 일자:
* 버전 내용: 우선순위를 적용한 스케줄링 알고리즘이 적용되는 것을 확인하는 예제
* 이전 버전 내용:
*/
#include <stdio.h>
#include <tchar.h>
#include <Windows.h>
int _tmain(int argc, TCHAR* argv[])
{
// 우선순위 NORMAL_PRIORITY_CLASS를 부여할 자식 프로세스
STARTUPINFO si_Normal = { 0, };
PROCESS_INFORMATION pi_Normal = { 0, };
TCHAR cmdNormal[] = _T("NORMAL_PRIORITY_CLASS.exe");
// 우선순위 BELOW_NORMAL_PRIORITY_CLASS를 부여할 자식 프로세스
STARTUPINFO si_Below = { 0, };
PROCESS_INFORMATION pi_Below = { 0, };
TCHAR cmdBelow[] = _T("BELOW_NORMAL_PRIORITY_CLASS.exe");
si_Normal.cb = sizeof(si_Normal);
si_Below.cb = sizeof(si_Below);
SetPriorityClass(GetCurrentProcess(), ABOVE_NORMAL_PRIORITY_CLASS);
// 자식 프로세스 생성
CreateProcess(
NULL,cmdNormal, NULL, NULL, TRUE,
0, NULL, NULL, &si_Normal, &pi_Normal);
CreateProcess(
NULL, cmdBelow, NULL, NULL, TRUE,
0, NULL, NULL, &si_Below, &pi_Below);
while (1)
{
for (DWORD i = 0; i < 10000; i++)
for (DWORD i = 0; i < 10000; i++); // Busy Waiting
//Sleep(10);
_fputts(_T("ABOVE_NORMAL_PRIORITY_CLASS Process\n"), stdout);
}
return 0;
}
[NORMAL_PRIORITY_CLASS.cpp]
/*
* Windows System Programming - 스케줄링 알고리즘과 우선순위
* 파일명: NORMAL_PRIORITY_CLASS.cpp
* 파일 버전: 0.1
* 작성자: Sevenshards
* 작성 일자: 2023-12-07
* 이전 버전 작성 일자:
* 버전 내용: 우선순위를 적용한 스케줄링 알고리즘이 적용되는 것을 확인하는 예제
* 이전 버전 내용:
*/
#include <stdio.h>
#include <tchar.h>
#include <Windows.h>
int _tmain(int argc, TCHAR* argv[])
{
SetPriorityClass(GetCurrentProcess(), NORMAL_PRIORITY_CLASS);
while (1)
{
for (DWORD i = 0; i < 10000; i++)
for (DWORD i = 0; i < 10000; i++); // Busy Waiting
//Sleep(10);
_fputts(_T("NORMAL_PRIORITY_CLASS Process\n"), stdout);
}
return 0;
}
[BELOW_NORMAL_PRIORITY_CLASS.cpp]
/*
* Windows System Programming - 스케줄링 알고리즘과 우선순위
* 파일명: BELOW_NORMAL_PRIORITY_CLASS.cpp
* 파일 버전: 0.1
* 작성자: Sevenshards
* 작성 일자: 2023-12-07
* 이전 버전 작성 일자:
* 버전 내용: 우선순위를 적용한 스케줄링 알고리즘이 적용되는 것을 확인하는 예제
* 이전 버전 내용:
*/
#include <stdio.h>
#include <tchar.h>
#include <Windows.h>
int _tmain(int argc, TCHAR* argv[])
{
SetPriorityClass(GetCurrentProcess(), BELOW_NORMAL_PRIORITY_CLASS);
while (1)
{
for (DWORD i = 0; i < 10000; i++)
for (DWORD i = 0; i < 10000; i++); // Busy Waiting
//Sleep(10);
_fputts(_T("BELOW_PRIORITY_CLASS Process\n"), stdout);
}
return 0;
}
어차피 지금 대부분 쓰시는 PC의 환경이 싱글코어인 분들은 없다고 생각합니다.
멀티코어 환경에서 실행하면 예상했던 우선순위 결과대로 절대 나오질 않습니다.
그래서 여기는 크게 중요하다고 하질 않았습니다.
실제로 우선순위에 대해서 정확하게 따지려면 쓰레드까지 가야 합니다.
지금은 앞에서 소개한 내용들이 더 중요하기 때문에 지금은 이런게 있다 정도로 이해하면 좋습니다.